Let’s talk about the benefits of Cloud Lakehouse. The most popular storage architectures for big data are data warehouses and data lakes. Have you considered switching from a data warehouse to a data lakehouse? A new approach has emerged that combines the best of both worlds called data lakehouse.
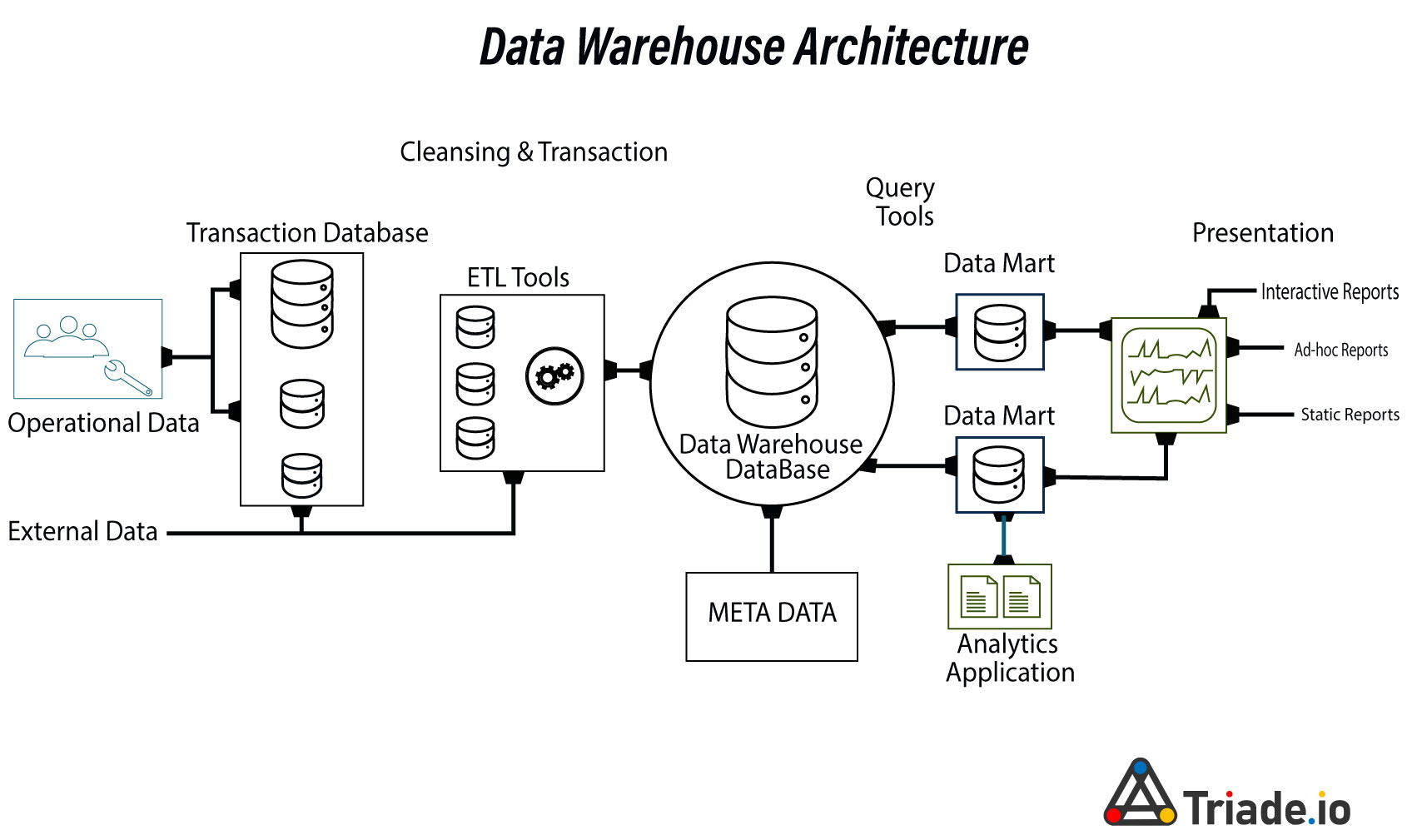
Understanding the various big-data storage and access methods is essential for building a reliable data pipeline for business intelligence (BI), data analytics, machine learning (ML) and Artificial Intelligence (AI) workloads, depending on your company’s demands. A data warehouse is a centralized data repository used by an organization to house enormous amounts of data from various sources. A data warehouse acts as an organization’s single source of “data truth” and is essential to reporting and business analytics.
Data Warehouses
Typically, data warehouses combine relational data sets from several sources, such as application, business, and transactional data, to store historical data. Before being loaded into the warehousing system, data is transformed and cleaned in data warehouses so that it may be used as a single source of data truth. Due to their capacity to quickly deliver business insights from all areas of the company, businesses invest in data warehouses.
Data Lakes
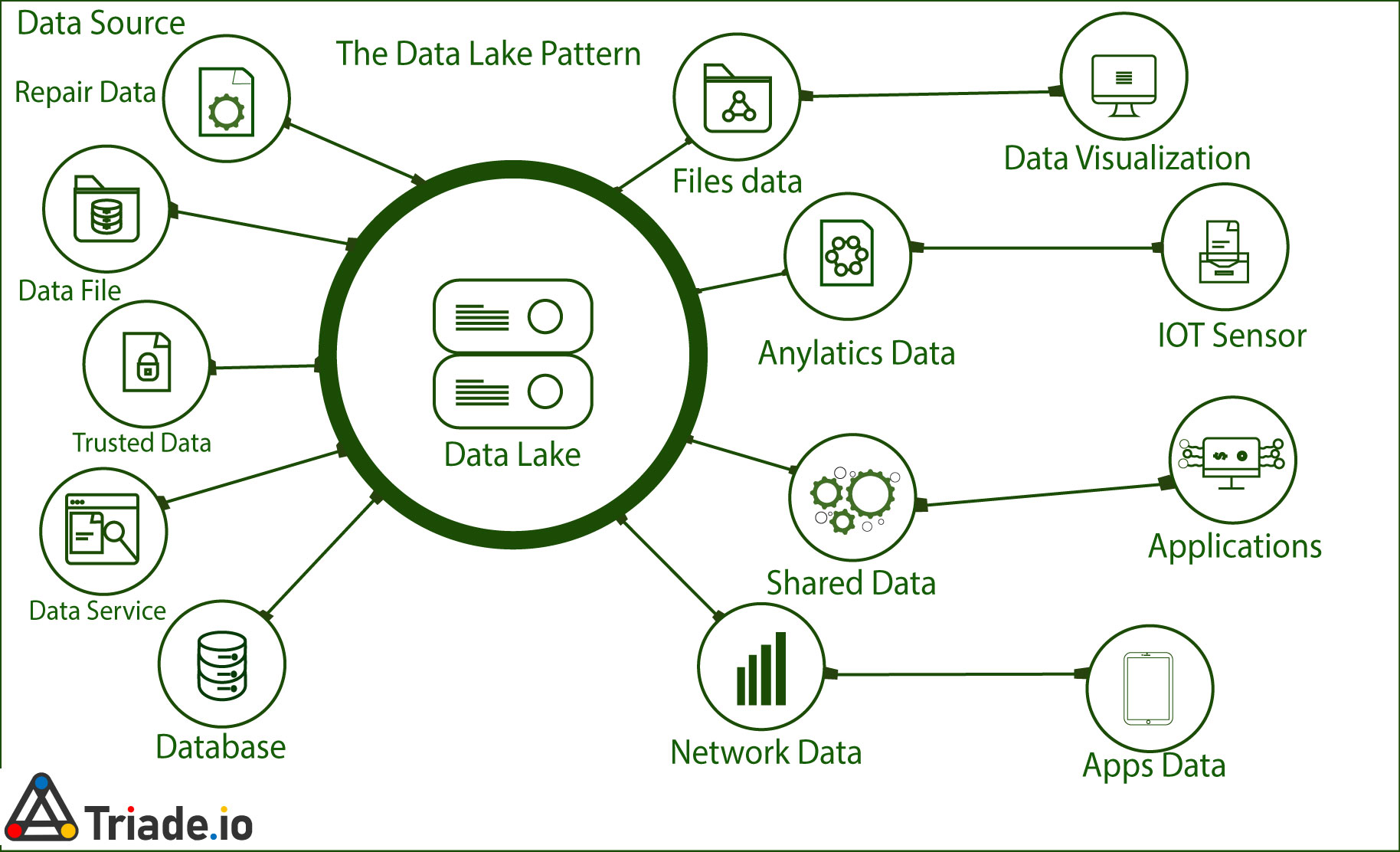
A data lake is a centralized, extremely adaptable storage space where massive amounts of organized and unstructured data are kept in their unprocessed, unaltered, and unformatted forms. A data lake uses a flat architecture and object storage in its unprocessed state to store data as opposed to data warehouses, which save relational data that has previously been cleaned. Data lakes, as opposed to data warehouses, which have difficulty handling data in this format, are adaptable, reliable, and affordable and allow enterprises to obtain advanced insight from unstructured data.
In data lakes, data is extracted, loaded, and transformed (ELT) for analysis purposes rather than having the schema or data defined at the time of data gathering. Utilizing tools for multiple data types from IoT devices, social media, and other sources, data lakes enable machine learning and predictive analytics.
Using Outdated Data Architectures Can be Challenging
Although they are sometimes chaotic and poorly managed, data lakes ETL store and compute huge data from the whole organization in low-cost object storage enabling common machine learning tools. Data lakes are inexpensive, yet they are frequently difficult to use.
High-performance SQL analysis and data layout optimization are made possible by data lakehouse’s improved query engine architectures. Users must switch between many systems because data warehouses weren’t designed to handle unstructured data types.
This data architecture requires routine maintenance and is a major concern for both data analysts and data scientists due to the numerous ETL phases and potential for error it contains.
Cloud Lakehouse Data Management: The Way Forward
The enterprise data landscape has benefited greatly from data lakes. Data lakes undoubtedly add a number of new possibilities to the infrastructure of organizational data management. Nevertheless, they lack some distinct characteristics of functional data stores and traditional data warehouses. This introduces the context of the more modern Data Lakehouse architecture.
Lakehouse Pattern in Emerging Data
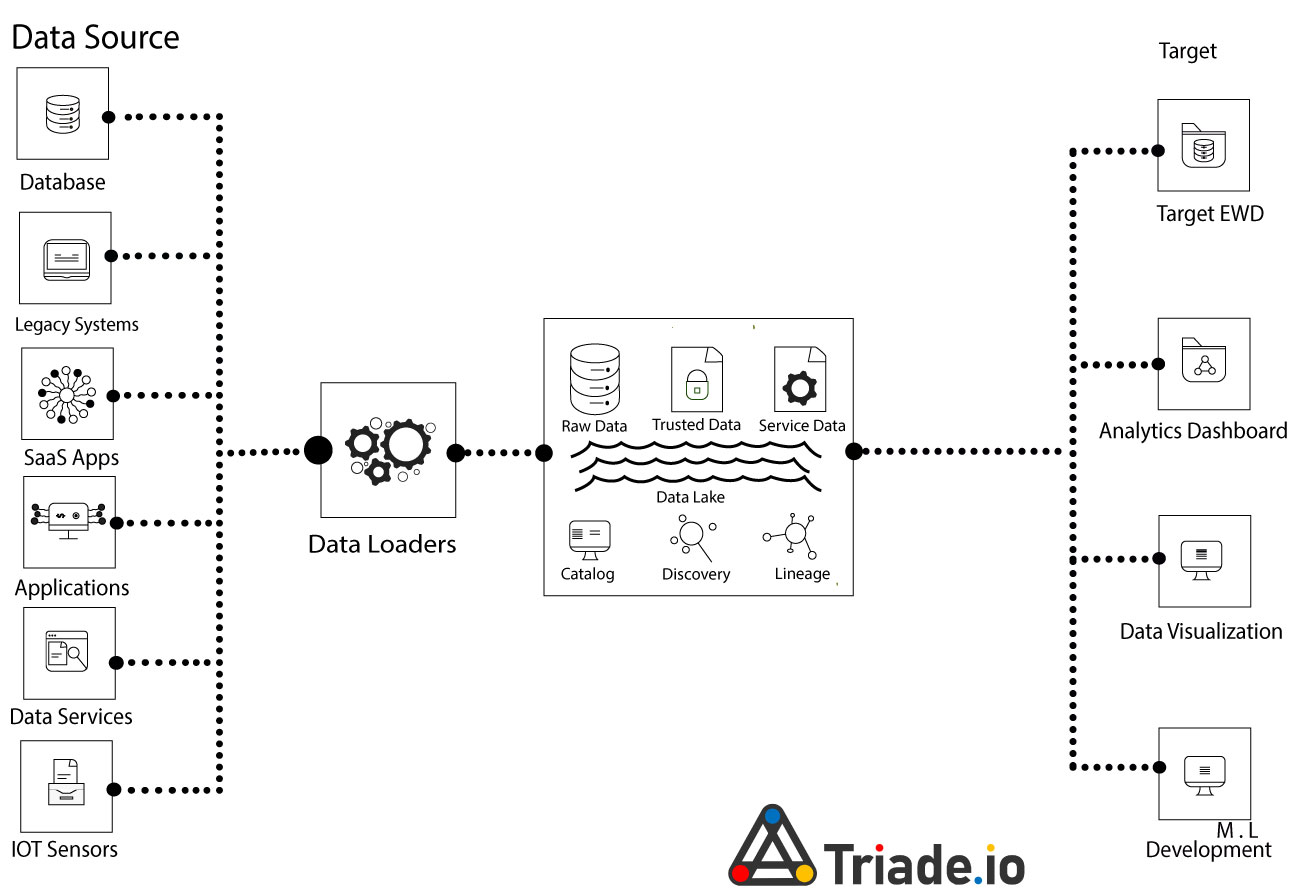
The concept of a data lakehouse combines elements of a data lake with a data warehouse to create a data management solution. Data warehouses’ administration and data architecture are used by data lakes, which are frequently more cost-effective for storing data.
Data lakehouses are made possible by an original, open system architecture that implements comparable data structures and data management capabilities to those in a data warehouse, right on the kind of inexpensive storage utilized for data lakes. Combining many systems into one enables data teams to work more rapidly without needing to access multiple systems. Data lakehouses ensure that the most comprehensive and up-to-date data is available for efforts like data science, machine learning, and business analytics.
The Technology and Future Ahead for Data Lakehouses
Data from operational systems must be collected and transferred into the target tier using different techniques for data lakes and data warehouses. Separate systems need large construction expenditures, continuous operational costs, and administrative overhead.
As a result, businesses started creating a two-tier architecture in which data is initially stored in a data lake. Following that, the data is processed using extract, transform, and load (ETL) or extract, load and transform (ELT) procedures into a structured SQL format appropriate for the data warehouse. However, this multi-tier architecture adds extra overhead, complexity, and delays.
A data lakehouse gathers all data onto a single platform using advancements in data structures, data processing, and metadata management so that it may be effectively shared for BI and machine learning. However, in order to enable ACID Transaction support, Schema Enforcement & Governance, and other common business capabilities, the data lakehouse must integrate new technologies. This is true even if it retains the majority of the underlying technologies of current data lake platforms.
The Delta Lake technological framework is one such example. Data lakes now have dependability thanks to the open-source storage layer known as Delta Lake. It allows for the construction of a Lakehouse architecture over data lakes. On top of already-existing data lakes like S3, ADLS, GCS, and HDFS, Delta Lake supports ACID transactions, scalable metadata handling, and integrates streaming and batch data processing, while SnowFlake supports ACID transactions natively as part of their Data Cloud PLatform.
Key Highlights of Data Lakehouses
The advantages of both the data lake and the data warehouse are combined by the lakehouse design, which offers:
– Cost-effective storage
– Support for all data types in all file formats – Schema support with data governance procedures
– Data reading and writing simultaneously – Improved tool access for data science and machine learning
– A single system to make it easier for your data teams to move workloads more quickly and correctly without requiring access to numerous platforms
– Scalability and flexibility
– The benefits of being open source
– Concurrent reading and writing of data
– Real-time capabilities for data science, machine learning, and data analytics applications
The objective is to extract business knowledge from unstructured data; how businesses handle their raw data is crucial.
Summary: The Benefits of Cloud Lakehouse Data Management
By managing your organization’s large data with a data lakehouse, you get:
- streamlined schema
- improved data governance
- reduced redundancy and data movement
- quicker and more effective utilization of team time
Speak with our specialists to fully utilize the potential that cloud lakehouse data management has to offer. Official Informatica partners include Triade. With the help of our cloud lakehouse data management solution, your business will have access to the finest managed services, the best people, and the best products to promote innovation, shorten time to market, and democratize data across all of your functional areas.
Our clients strongly value our expertise and vendor-neutral strategy. Our staff has extensive knowledge of many different cloud platforms, including Snowflake, Databricks Delta Lake, Microsoft Azure, Google Cloud Platform, and Amazon Web Services. To hasten the delivery of your data, get in touch with us.


