Snowflake started out as the top cloud storage solution. It was designed with the intention of offering cloud scalability and basic data storage. With its detached storage and processing, it provides remarkable flexibility from the start.
It handles many additional scenarios that the majority of data engineers and analysts don’t want to think about, such as table clustering, auto-scaling, security, and caching.
The Highlights of Snowflake
- Snowflake was created using AWS cloud services. First powered by Amazon Web Services (AWS), it is now also available on Microsoft Azure and Google Cloud Platform. As a result, Snowflake has an intriguing relationship with these cloud service providers, acting as both a client and a competitor.
- Large amounts of data are easier to handle, collect, and analyze for businesses because of this technology. Instead of having to pull data from several sources, Snowflake enables you to keep your data in one location.
- You may achieve this without a large team of IT specialists or data scientists. It takes care of all the labor-intensive work. Snowflake enables businesses to store and examine their customer data. It serves as more than just an analytics tool; it also works well for businesses that need to consolidate enormous amounts of data.
- A complete end-to-end solution for storing and analyzing your digital information, Snowflake is more than just another database. It integrates ingestion, processing, security, governance, and collaboration, all of which are essential for you to manage your business at scale. It is, thus, a complete solution for managing huge data processing requirements.
Introducing Snowpipe by Snowflake
Snowpipe is a privately owned continuous data loading method developed by Snowflake. Data from a stage is taken and loaded into a table via Snowflake elements called “pipes,” which contain a COPY command.
A stage is a place in the cloud where datasets are kept, internally (inside Snowflake) or externally (on a cloud platform like AWS S3 or Azure Data Lake Storage). You can use a public REST API endpoint or a cloud event messaging service/solution like AWS SNS, Microsoft Azure, or GCP (Google Cloud Platform) to access Snowpipe.
For instance, when log files are uploaded to an AWS S3 bucket, Snowpipe is notified by AWS SNS or S3 Event Notifications that fresh data is now accessible. Snowpipe seizes the updated information and adds it to the desired table.
The advantages are numerous:
- You don’t need to configure or monitor resources because it’s serverless.
- As opposed to the extensive billing strategy for virtual warehouses, you are only charged for the resources that Snowflake utilizes to transport the data.
- Since it is continuous, it is a useful strategy for minor progressive loads or data that flows continuously.
- This is an easy approach to import data using native technology into Snowflake if you already have a cloud data lake.
Snowpipe is a managed service for conducting ETL operations including transformations and validations as well as continuously loading data into your warehouse.
Because Snowpipe is cloud-based and managed via Snowflake, you don’t have to worry about infrastructure administration or capacity planning; instead, you can concentrate on creating fantastic applications that sit on top of your data.
Key Snowflake Components in Data Engineering
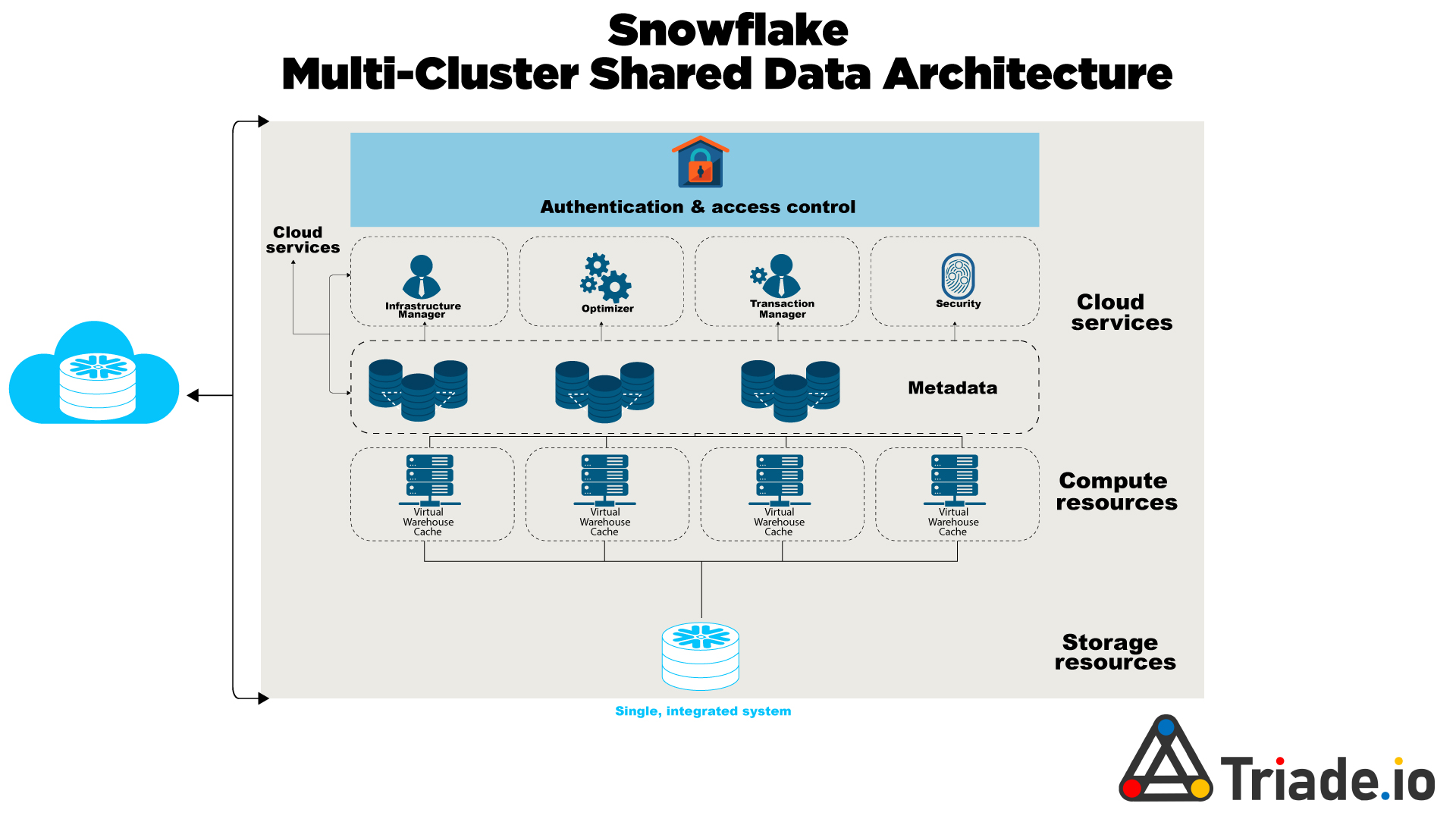
Snowflake Multi-Cluster Architecture
Here are some key Snowflake functions in data engineering;
1.Stream function
With the help of the stream function, you can keep track of changes to a table’s data as they occur. Additionally, you can record every data entry, update, and deletion. Note: changes that occur after the stream is activated can be captured, but those that occur earlier cannot.
After the stream is built, you may either query it or use it for consumption. If you consume the stream, the stream will become empty after you insert the data from it into another table. When constructing continuous data pipelines, this is quite useful. Three more hidden columns that track the metadata about the modifications are added to a table when a stream is created.
2. Zero-copy cloning
In a standard RDBMS system, when you copy a table from one database to another, the table and its contents are also replicated, meaning that the data is replicated again and memory requirements are increased. With Snowflake’s zero-copy cloning functionality, you may duplicate a table without replicating all of the data.
The nicest thing is that you only pay for one copy of the data. You can utilize zero-copy cloning, for instance, if you need to replicate data from a specific table from the Production system to the Development platform. Here, just Production is used to store data.
3. Serverless tasks in Snowflake
The serverless compute model for tasks enables you to rely on compute resources managed by Snowflake instead of user-managed virtual warehouses. The compute resources are automatically resized and scaled up or down by Snowflake as required for each workload. Snowflake determines the ideal size of the compute resources for a given run based on a dynamic analysis of statistics for the most recent previous runs of the same task.
If you prefer, you can alternatively manage the compute resources for individual tasks by specifying an existing virtual warehouse when creating the task. This option requires that you choose a warehouse that is sized appropriately for the SQL actions that are executed by the task.
Snowflake in Data Engineering: Key Roles & Best Practices
1. Minimizing data controls
Although human audits and validation are necessary for many data governance measures, Snowflake offers capability to minimize the amount of controls needed. Snowflake can occasionally simplify data governance controls.
Your data must be accessible whenever your company requires it. Snowflake inherits many of the high availability capabilities (similar to other cloud providers) and is accessible on AWS, Azure, and Google Cloud Platform.
In addition to the variety of cloud provider offerings, Snowflake adds the following features:
- Data node fault tolerance
- Easy data distribution among several availability zones
- Replication and fail-over of data (cross-region and cross-cloud)
- Time travel for data backups and retrieving deleted data
- Separating storage and computing resources
These extra features are essential for preserving data availability. For instance, an AWS availability zone experiences a brief outage. Snowflake will automatically handle failure circumstances and reroute your request away from the unavailable zone since your database and your processing assets have been dispersed across different availability zones.
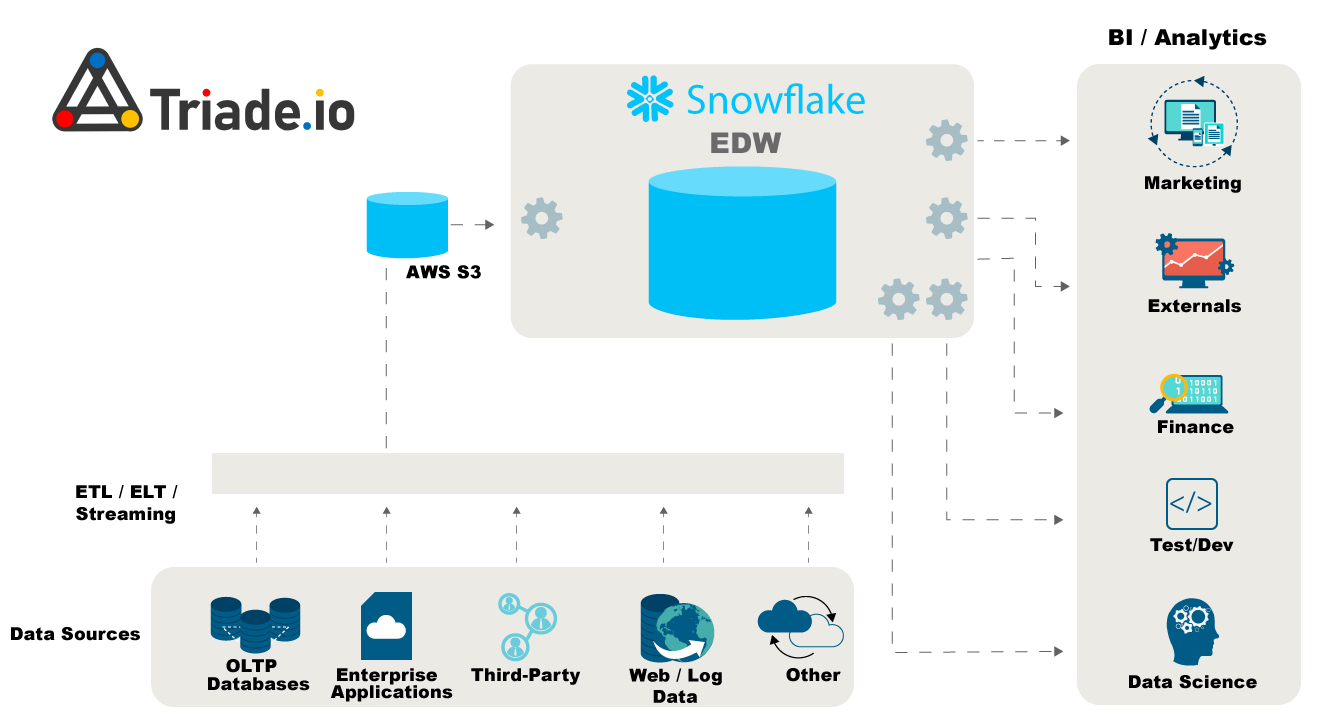
2. Reducing the requirement for data pipelines
The centralized data model used by Snowflake eliminates the requirement for data pipelines to transfer data between locations and further improves the accessibility of your data across your company.
Several distinct data import procedures are available in Snowflake (like Stages, SnowPipe, and others). These procedures can guarantee that data complies with specific requirements. The format that the data is supposed to follow is defined when these intake operations are defined.
Your data types and their precision are enforced by this schema specification. The centralized data approach used by Snowflake also encourages usability. Snowflake provides for numerous accounts to separate out business expenditures and organize data by business unit, even though many businesses may only have one.
3. Improved Data Sharing
Eliminate data silos; instantly and securely share data across your entire business ecosystem. Snowflake enables you to set up and manage data sharing with ease, whether you need to share data with partners or other parties. Simply sending an email invitation to collaborators will allow you to request their help on a project.
Determine who sees what data, and ensure all your business units and business partners access a single and secure copy of your data. With Secure Data Sharing, no actual data is copied or transferred between accounts. All sharing uses Snowflake’s services layer and metadata store. Shared data does not take up any storage in a consumer account and therefore does not contribute to the consumer’s monthly data storage charges. The only charges to consumers are for the compute resources (i.e. virtual warehouses) used to query the shared data.
4. Enhanced Data Analysis
Snowflake can be used to analyze machine data, such as that from IoT devices or sensors, as well as any kind of unstructured or semi-structured data, like that from audio, video, and text files, as well as structured business intelligence (BI) workloads like those from online transaction processing (OLTP) databases.
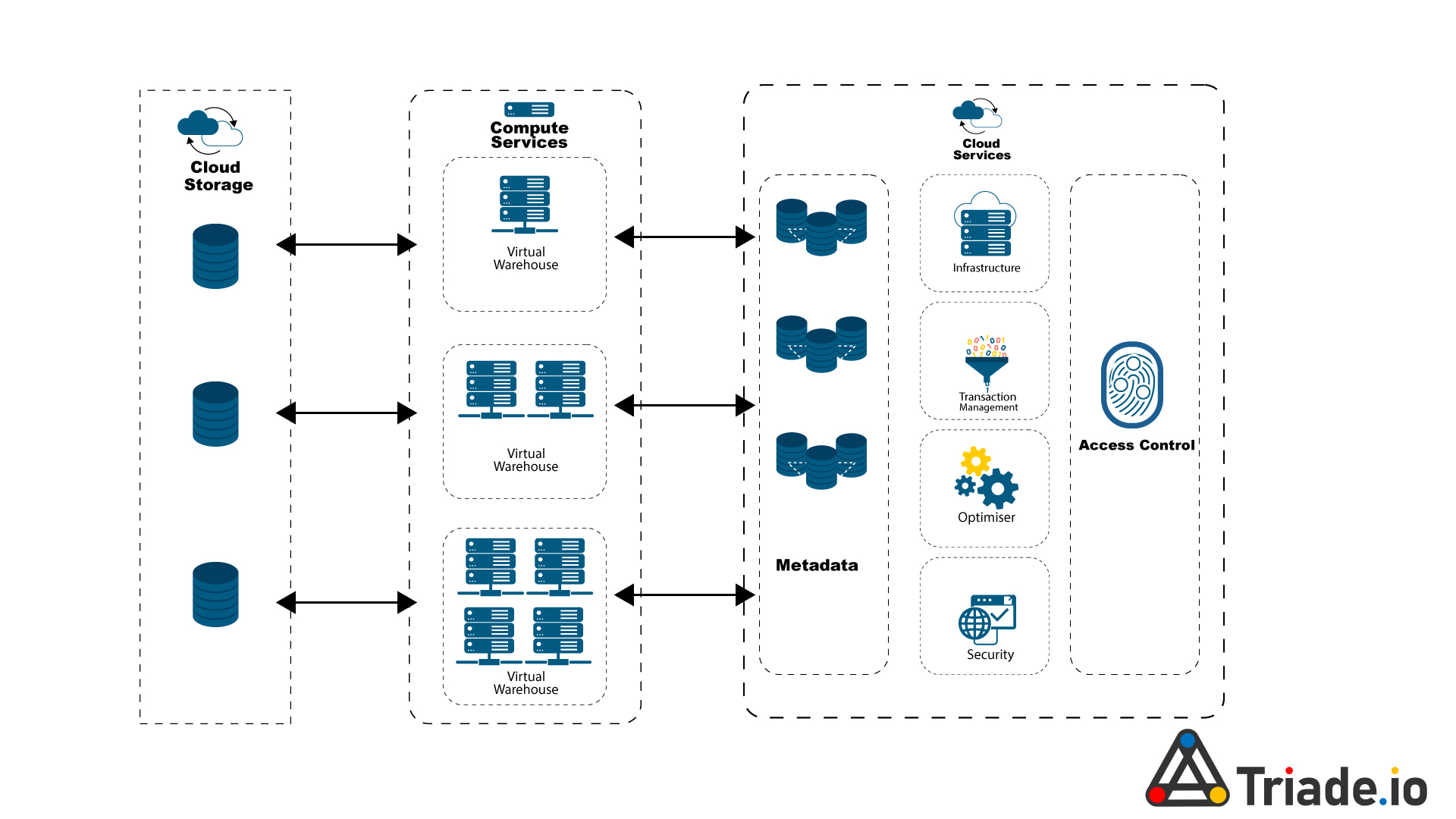
Snowflake is a platform that isn’t a standard columnar database or a Hadoop platform; it can manage enormous volumes of data at rapid speeds with exceptional performance. No matter the size, shape, or location of the information, it may be used by enterprises to execute advanced analytics on petabytes or even exabytes of data.
You may even build up permissions based on the roles that each collaborator plays inside your organization; for example, you could grant someone read-only access or full write privileges if that is necessary for their job.
You can easily manage the entire process from within your Snowflake dashboard after setting up your users’ roles and giving them the proper privileges and access.
5. Advanced Big Data Solution for Business
Snowflake is a Data-Warehouse-as-a-Service. By storing all of the company’s data in one location, it enables businesses to scale up their analytics requirements and manage large amounts of information quickly.
Whether it’s transactional or real-time sensor data, Snowflake makes it simple to store, query, and analyze whatever big data your business generates, whether it’s structured or unstructured.
Snowflake’s massively parallel processing architecture also enables it to scale effortlessly as your organization expands while running sophisticated queries at breakneck speed.
6. High Scalability & Improved Maintenance
With Snowflake’s elastic scalability, you can add more compute resources right away as needed without affecting ongoing business activities or platform-running apps. Snowflake’s “self-healing architecture” guarantees high availability by constantly checking the health of your cluster and taking proactive corrective action if a fault arises – all without interfering with service delivery or resulting in downtime.
By lowering the amount of time spent manually managing databases and conducting database maintenance activities, this can save teams hundreds of thousands of dollars annually freeing them up to engage with innovation and create fantastic new solutions for your customers.
To transform the data ingestion, storage, compliance and sharing for your business, talk to us.
- Zero-maintenance solution and seamless scaling
- Data-driven insights for improved operability and decision-making.
Get in touch with us to start today.


