A new platform termed a data lakehouse combines the capabilities of a data lake with a data warehouse. When deliberately coupled in a larger data storage/management system, data lakehouses combine the freedom of a data lake for storing unstructured data with the data management capabilities and features of a data warehouse. Users can benefit from the best of both worlds by integrating these two data solutions.
A data lakehouse can manage a number of key components of data to serve use cases often connected to a data lake or warehouse. One of the challenges solved is the combination of simple data intake capabilities (for raw data) with the ability to enable high-performance business intelligence (BI) employing extract, transform, and load (ETL) processes to organize data.
Data Lakehouse Architecture
One of the first providers to adopt the Lakehouse was Snowflake as their solution always aimed to address both use cases in a one stop shop and simplify the data platform solution, followed by AWS and Databricks who currently advertise more on Lakehouse as it solved many of the customer issues. Currently you can find the concept widely adopted by all Cloud Providers and Informatica is really well-positioned to address the Data Management layer. The following five layers are commonly present in data lakehouse systems.
1. Ingestion Layer
Data is gathered from the source and delivered to a raw/ingestion layer from a variety of sources and latencies. It connects to internal and external resources via a variety of protocols, combining data streaming and batch processing (i.e., an RDMS, NoSQL database, CRM application, etc.). During the intake phase, components such as Apache Kafka for streaming, Change Data Capture mechanism, PIPE’s, API, Rest/Web Services, ODBC and JDBC for data ingestion may be employed.
2. Storage Layer
The data is kept in the ingestion layer as needed due to reasonably priced platforms like Amazon S3, Microsoft ADLS and Google Cloud Storage as well as due to the advanced triggering and archiving build in mechanism brought in by the Object Store layer. Many APIs and other components can access and use the data since the client has tools for reading objects from the data store. Although it can also be used on-premises, a data lakehouse is especially suitable for cloud data services that separate the storage from the compute cost creating huge savings to your bottom-line.
3. Metadata Layer
This is the fundamental feature that sets data lakehouses apart from other data management solutions. The metadata layer is a central catalog that provides information about each object in the data lakehouse, enabling users to search for relevant data, understand their lineage, where they came from and where they go to, what are the calculation applies, what the data domains are, which fields are primary key, unique key, how the data is classification. It allows developers to build reliable code and automation as well. It allows managers to better estimate effort to complete their projects since they can quickly gauge complexity to build out data projects.
The metadata layer is the fundamental component of a data lakehouse that distinguishes this design. It is a single catalog that offers metadata (information about other data pieces) for all items stored in the lake and allows users to employ administration capabilities like
A consistent version of the database is seen by concurrent transactions thanks to ACID transactions –
- caching to save cloud object store files
- zero-copy cloning, which replicates data objects, and indexing
- data versioning, which saves particular versions of the data, and adds data structure indexes for quicker query-making
The metadata layer also enables the use of DW schema architectures like star/snowflake schemas, the implementation of schema management, and the provision of data governance.
The metadata layer is a single catalog that contains the metadata for items in the data lake. The data warehouse features that are available in relational database management systems are provided by this layer (RDBMS). For example, you can define features to improve RDBMS performance and implement upserts.
It offers features for data governance and auditing while enabling enterprises to manage schemas. Users can monitor data quality by rejecting writes that don’t adhere to the schema thanks to the evolution and enforcement mechanisms included in schema management. Auditing and access control are made simpler with a uniform management interface.
4. API Layer
This layer houses a number of APIs that let users swiftly process data and carry out complex analytics operations. An example of this is how a metadata API aids in locating the items needed for a specific application. Direct queries of the metadata layer are made possible by some ML libraries’ ability to read formats like Parquet. Other APIs aid programmers in streamlining the data transformation and structure.
5. Consumption Layer
The final phase of general data flow in a data lake and lakehouse design is the consumption zone.The business intelligence (BI) dashboards, ML jobs, and other analytics-related tasks are supported by the tools and programmes at the data consumption layer.
Through the analytic consumption tools and SQL and noSQL query capabilities at this layer, the findings and business insights from analytic projects are made available to the targeted users, be they technical decision-makers or business analysts. This layer is crucial to provide your business areas with access to important data and insights for data-driven decision making. Check out some of our technology partners and expertise that will help you in utilizing this layer to align with your business goals.
The Relevance and Use Cases of Data Lakehouse
The lakehouse is a new data solution concept that has independently arisen over the past few years across numerous clients and use cases who needed a simplified approach to address Data Management leveraging Data Warehouse / Lakes combined use cases for decision assistance and corporate intelligence. Data warehouse technology has developed significantly since its start in the late 1960-70, followed by the MPP architectures introduced in the 1983 gaining real popularity on the early 2000, then came the Hadoop (2003) and Map Reduce (2004) to resolve the risen of data and data formats, the Data Lakes was first introduced in 2011, gaining popularity in 2015 with the advance and adoption of Cloud Data Provider and services like Amazon s3, Microsoft ADLS and Google Storage to store the Raw Data Like format in a cheap and scalable way.
Despite the fact that warehouses were excellent for structured data, many modern businesses must deal with unstructured data, semi-structured data, and data that is highly variable, dynamic, and large in volume. Many of these use cases are not well suited for data warehouses, and they are not the most economical either. Architects started to imagine a single system to contain data for numerous analytic products and workloads as businesses started to acquire massive amounts of data from numerous sources.
Data lakes are effective at storing data, but they are missing some key components: they do not guarantee data quality, do not enable transactions, and it is difficult to blend batch and streaming jobs with append and read operations. These factors have prevented many data lakes from delivering on their promises, which has frequently resulted in the loss of numerous data warehouse advantages.
What purpose does the data lakehouse architecture serve? Organizations looking to advance from BI to AI are a crucial segment. Simply because the insights that can be derived from unstructured data are so rich, organizations are turning to it more frequently to guide their data-driven operations and decision-making.
Resolving Data Governance Issues
It is possible to add all data to a data lake. However, there would be substantial data governance issues to solve, such as the likelihood that you are handling personal identified information (PII) or personal health information (PHI). This would be addressed by a lakehouse architecture that counts on a sophisticated data governance solution that allows for automatic classification of data type and content tagging them as appropriate to align and enforce the defined compliance policies, procedures and standards, as well to have applied data anonymization.
Improving Data Analysis
As more businesses realize the benefits of combining unstructured data with AI and machine learning, the data lakehouse method is one that is expected to gain popularity. It represents an advancement in data analytics maturity over the siloed data lake and data warehouse architecture.
With time, lakehouses will fill in these gaps while maintaining their fundamental advantages of being easier to use, more affordable, and better suited to a variety of data application needs if implemented in the right way.
To unleash the potential cloud lakehouse data management offers, talk to our experts. Triade is an official Informatica partner and SnowFlake partner. Our cloud lakehouse data management solution provides you and your organization with the right products, best people and services to drive innovation, reduce time to market and democratize data across all your business.
Our experience and vendor-agnostic approach are highly regarded among our clients. Our team expertise spans through Snowflake, Databricks Delta Lake, Microsoft Azure, Google Cloud Platform, Amazon Web Services, and many others. Get in touch with us to speed up your data journey.
Why Work With Triade on Your Cloud Data Lakehouse?
- Triade is a preferred partner – offering top tier people, technology & solutions – to support your path to a cloud data platform, regardless of the stage of your data maturity
- The Triade team has been working on Data Management projects with Informatica solutions for over 18 years with several Informatica-Certified experts
- Snowflake SnowPro Certified Consultants
- Highly regarded Informatica partner in the United States, India, Brazil, Mexico and beyond
- Our onshore, nearshore and offshore operations ensure we deliver to our clients on their business needs and budgets.
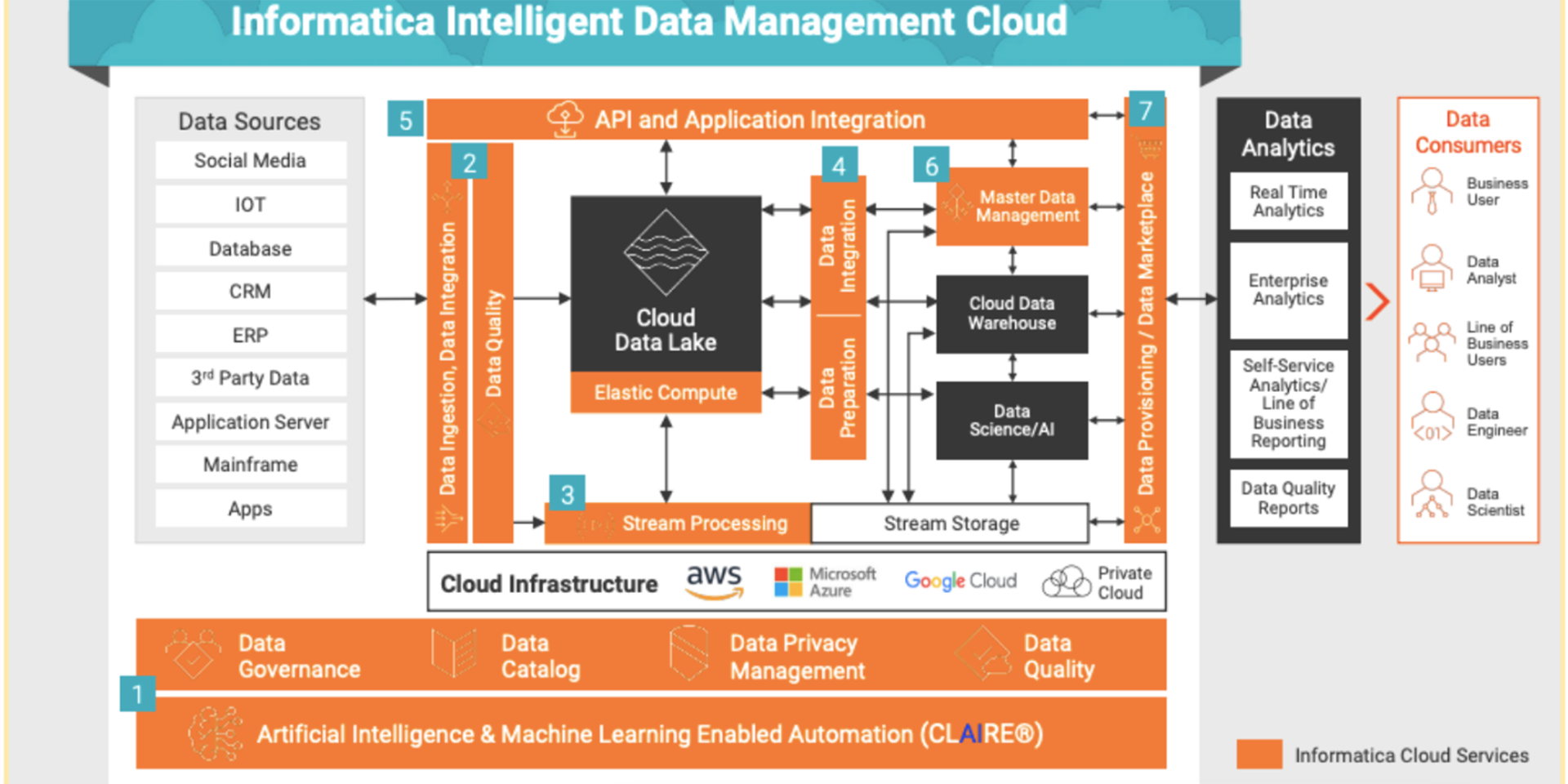
Intelligent Data Management Cloud (IDMC) and Cloud Data Integration (CDI)
The main features of the Informatica Cloud Data Integration:
- Codeless integration
- Mass ingestion for files, DB and streaming
- Push-down optimization
- Serverless and elastic scaling
- Spark-based processing in the cloud
- Codeless integration
- Broad connectivity
- Stream processing
- MLOps
Informatica Data Catalog, Former EDC Now on Cloud
The main features of the Informatica Enterprise Data Catalog:
- Data discovery
- End-to-end lineage
- Metadata – technical, business, operational, usage
- Connect and scan metadata – databases (DW, DL), apps, ETL, BI tools and others
- Common metadata foundation


