As many businesses struggle to make sense of all their data, choosing a data platform that can handle enormous volumes of big data, fast speeds, and reliability—not to mention the ease of use—is their first priority.
As part of a long-term strategy commitment to transform into a cloud-first, data-driven company, many already use cloud data platforms or are considering doing so. Snowflake, a strong contender with almost 20% market share, supports multiple cloud infrastructures, including those from Amazon, Microsoft, and Google Cloud Platform (GCP). Snowflake users can focus on data analysis rather than managing and optimizing thanks to its highly scalable cloud data warehouse.
In this blog, we will walk you through the top use cases of Snowflake, challenges to overcome, and more. So, let’s start from the basics before we delve deeper!
Snowflake: Origin, Evolution & Importance
One of the most well-known Software-as-a-Service (SaaS) cloud data warehouses, Snowflake was founded in 2012. It allows data storage and computing to scale independently and is constructed on top of the infrastructure of the following cloud platforms:
- Amazon Web Services (AWS)
- Azure Cloud by Microsoft
- Cloud Platform by Google (GCP)
It can be used for data lakes, operational data stores, data warehouses, and data solutions because it is a multi-purpose cloud data warehouse. It provides data ingestion, storage, processing, and analytical solutions that are far more rapid, user-friendly, and adaptable than other alternatives.
Performance and operational cost are balanced by its decoupled compute and storage architecture with automatic up and down scalability. Snowflake offers outstanding manageability for data warehousing, data lakes, data analytics, data access and governance.
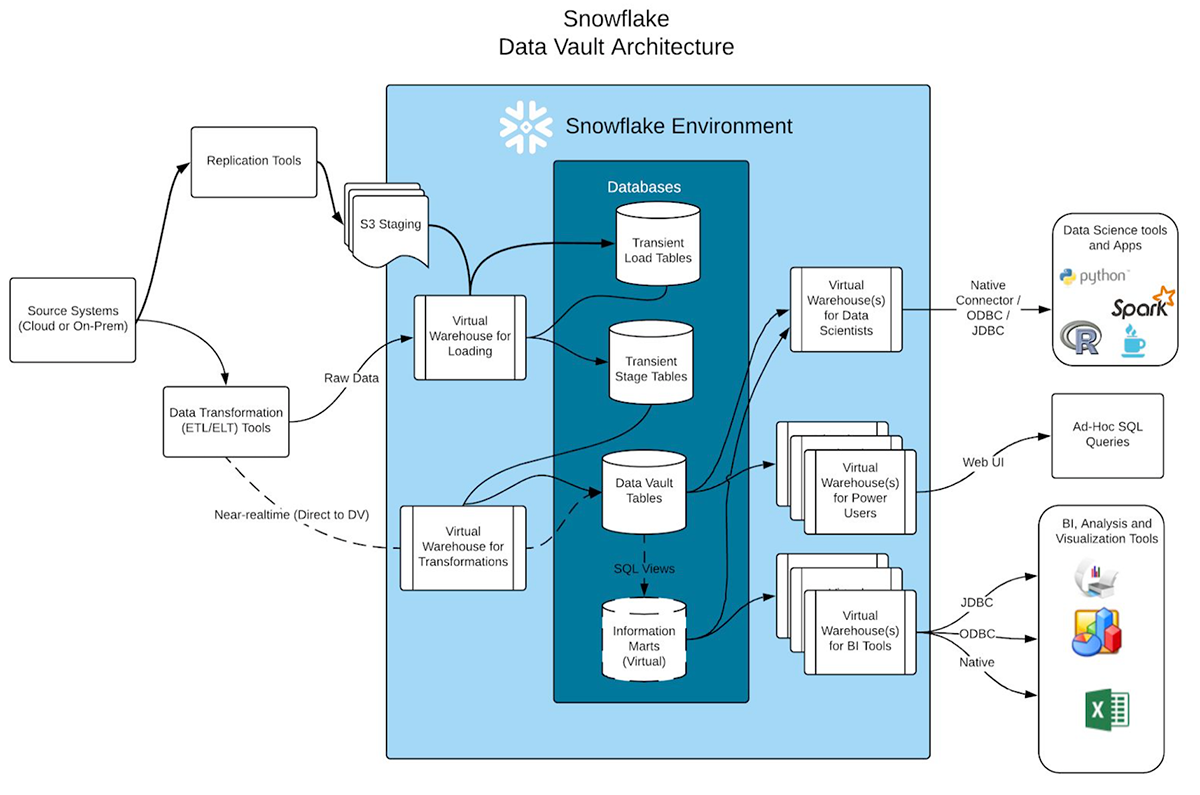
Snowflake Data Vault Architecture – Snowflake Community
A remarkable aspect of Snowflake is its ability to manage virtually endless amounts of concurrent workloads, guaranteeing that your users can always complete their tasks when they are due. In comparison to on-premise systems, Snowflake offers data warehousing, processing, and analytical solutions that are substantially faster, easier to use, and more flexible.
Snowflake combines a novel cloud-native architecture with a whole new SQL query engine. In addition to various special features and functionalities, Snowflake gives the customer all the capabilities of an enterprise analytical database.
The Top Eight Use Cases of Snowflake
Here are some of the top Snowflake use cases to give you an overview of when to consider it.
Use case 1: Session Transactions and Data Storage
Session data is present in enormous amounts of business settings. But not all problems with data analysis are related to quantity. Data must be maintained up to date and fresh. Your ETL and reload may be time and resource constrained even with well-designed processes.
Even if you expand the overall capacity of your servers to address your data volume problem, you might still need to replicate the upgrade in the long term. Even with periodic system backups, storage systems are another issue that can cause additional overheads.
Your retail transaction warehouse has problems already, but when you add a growing list of present and potential data users to the mix, the issues only get worse. Snowflake plays a crucial role here by working in the following way.
Abstraction: Snowflake’s processing abstraction combined with warehouses enables auto-scaling of compute capacity to match the needs of the company without modifying the infrastructure.
Role-based access: Users can encrypt personally identifiable information (PII) data or restrict the fields that are accessible in Snowflake by using Secured Views. As a result, teams can access the information they require to complete their tasks while still adhering to governance norms.
Backups: Snowflake’s Time Travel function creates 90-day backups that are regularly stored. If some problem occurs, you can easily roll back to a previous version of the data set or even undrop a table.
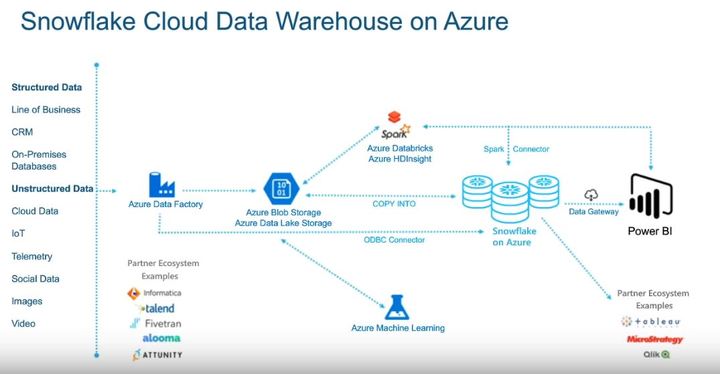
Snowflake Cloud Data Warehouse on Azure – Snowflake Community
Use case 2: Data Operations in Machine-Learning Environments
To precisely forecast developments in the financial industry, a time machine would be very handy. We might all agree that possessing a time machine is unrealistic, but you can devise a simple fix to increase your chances of being accurate while reducing the risks associated with your decisions.
You would use previous market and trade data, news, and legislation data when developing this kind of solution. All that affects how your machine learning application analysis should work to your advantage so that you can produce forecasts that are more accurate.
Inevitably, a part of this data will need to be collected and processed manually, reducing automation levels. The system must regularly be reprogrammed as the datasets grow to improve the functionality, and network operators must be particularly attentive so they have enough time to act on the data it generates.
Of course, more users will be keen to access and utilize the solution’s results as you add new data and efficiency to your datasets. Numerous capabilities that Snowflake provides can assist in meeting the requirements of this kind of system and application:
Manually ingested data: SnowSQL enables the entry of manually curated data right into tables.
User-defined functions: Snowpark enables you to create user-defined functions (UDF) written in diverse programming languages such as Java, JavaScript, Python and SQL which may be used in conjunction with stored procedures to offload a significant amount of processing to natively running computers.
Multi-cluster warehouse: In Snowflake, you can provide your team with access to a sizable, multi-cluster warehouse that enables you to process several queries with high load at once with prompt results. Also, you can monetise the sizable and priceless dataset you’ve gathered using the Snowflake data marketplace.
Use case 3: Seamless Ingestion and Integrations
Snowflake adapts to different data integration patterns, such as batch, near real time, and real time, without any issues. Consider your data loading use cases when determining the optimum pattern. You might want to combine both static batch processing for data given on a set timetable and dynamic patterning for data delivered on demand. Evaluate your needs so that you can link your data sourcing needs and delivery SLAs to the right ingestion pattern.
When data is ingested by an event-based workflow, your SLA is improved, data is delivered quicker, efforts are avoided when delays occur, and static dependency is changed into an automatic triggering mechanism.
ETL tooling is the next step after identifying integration principles. Numerous integration vendors and technologies like Informatica are supported by Snowflake. Additionally, many of these have created a native connector for Snowflake. Also, Snowflake allows no-tool integration using Python and other open source languages.
Examine the solutions in light of data volume, capacity strategy, and usage expectations you will have in order to select the best panel. Additionally, take into account whether it can run SQL, move down or process in memory leveraging Snowflake warehouse for processing. Big Data use cases benefit greatly from the push down technique since it removes the application’s storage constraint.
Use case 4: Business Intelligence
Data warehousing is a critical part of any business intelligence operation. Using Snowflake, your organization can implement data warehouses faster, which can be used for ad-hoc analysis by running SQL queries. Snowflake can easily be integrated with business intelligence tools such as Looker, PowerBI, QuickSight, and Tableau.
Use case 5: Machine Learning
A lot of businesses employ machine learning algorithms to forecast data. Data engineers must construct, test, and choose the best attributes for their ML models as part of feature engineering. Once models are put into use, gathering a sizable amount of clean, fresh, and historical data to guarantee ML model accuracy becomes the main challenge.
To support each experiment, complete datasets must be copied, which may be done with Snowflake’s zero-copy cloning function. To prepare data fast and create Machine Learning (ML) models, Apache Spark may also be used and directly connected to Snowflake. Programming languages that are used for machine learning, like Python, R, Java, and C++, are supported by Snowflake (ML).
Use case 6: Data Security & Governance
Data security and governance are crucial when dealing with sensitive business and customer data. Protecting the data from external and internal data breaches is difficult and time-consuming with a standard data warehouse.
In order to safeguard the data and set up policies and data access controls, Snowflake offers integration with a variety of third-party data governance technologies, including Immuta, Collibra, Informatica, and many others.
When compared to conventional data warehouses, Snowflake helps keep performance high while lowering operational costs. Using Snowflake, data replication between databases and tables becomes seamless and simple.
Use case 7: Powerful Data Processing
Data scientists must have access to sufficient compute power to evaluate and prepare the data before putting it into sophisticated machine learning models and deep learning tools. A computer approach called feature engineering comprises transforming unstructured data into more useful characteristics that produce precise predictive models. New predictive features:
- can be time-consuming and challenging,
- may require expertise in the domain, and
- require acquaintance with the unique specifications of each model.
Traditional data preparation platforms, such as Apache Spark, are overly complicated and ineffective, which leads to data pipelines that are brittle and expensive. Data engineering, business intelligence, and data science workloads won’t compete for resources because of Snowflake’s innovative design, which offers a separate computing cluster for each job and team.
The majority of the automated feature engineering work performed by Snowflake’s machine learning partners is transferred into Snowflake’s cloud data platform. Using Python, Apache Spark, and ODBC/JDBC interfaces provided by Snowflake, manual feature engineering can be carried out in a variety of languages. Data processing with SQL can boost speed and efficiency by up to 10 times while opening feature engineering to a wider range of data experts.
Use case 8: Micro-Partitioned Data Storage
Unlike typical static partitioning – which requires a column name to be manually supplied to separate the data – all data in Snowflake tables is automatically partitioned into micro-partitions, which are contiguous storage units.
The data size of a micro-partition varies from 50 MB to 500 MB. The most efficient compression algorithm is automatically allocated to each column of each micro-partition by Snowflake’s Storage Layer.
Next, the rows in tables are converted into distinct micro-partitions grouped in a columnar fashion. While loading or entering data, tables are dynamically partitioned based on the data’s sequence. All DML operations like DELETE and UPDATE use the underlying micro-partition metadata to enable and keep table maintenance as easy as possible.
When we discuss data analytics, we are talking about GBs of data with countless millions of rows. The best place to store it is not on your computer’s hard drive. Most small and even mid-sized organizations lack high-end data centers with unlimited storage and incredible computing power.
Herein lies Snowflake’s role. Snowflake is a database and data warehouse solution that you can use with either AWS, Azure, or GCP. It provides a stand-alone data warehousing solution with a SQL ANSI language framework that can be scaled up and down at any moment as discussed above.
Questions to Answer before and after You Choose Snowflake
1. What challenges are you aiming to solve?
Conventional data warehouse issues:
- Performance concerns when trying to load and query data at the same time
- Inadequate management of several data sources
- Costly, drawn-out, and unpleasant data recovery method
- Inconsistent, unreliable data, and poor data exchange are caused by the absence of a single source of truth
Snowflake has a distinctive scalable architecture that divides its computation and storage resources and is created specifically for the cloud. It has a hybrid feature which blends the shared architecture and shared disc architecture of traditional warehouses along with the massively parallel processing (MPP) capability. With pay-as-you-go service, Snowflake provides independently scalable, practically infinite storage and computation capabilities.
Snowflake’s multi-cluster, shared data architecture consists of three layers:
- Compute Layer, sometimes referred to as Virtual Warehouse, is a scalable, elastic, and resizable layer.
- Holding Layer (leverages hybrid columnar, compressed storage mechanism)
- Services Layer (takes care of all metadata, security, and optimization aspects of data management)
Solution 1: High performance with high elasticity and high availability
Solution 2: Snowflake can intelligently handle incoming data’s volume, variety, and speed
Solution 3: Before Snowflake, recovering an object was never easy!
Solution 4: Coherent Data Centralization, Democratization, and Sharing with Snowflake
2. What methods are currently in place for data loading?
The Snowflake Web Interface is the easiest way to do data input into Snowflake. The wizard allows for the loading of a small number of files that are not very large (up to 50MB).
Once the table has been created, click on it to see the table details page and select the option to load the table. The Load Data wizard opens when you choose the Load Table option, loading the file into your table.
Method 1: Data Loading to Snowflake Using Snowpipe
Snowpipe can also be used to automate large data loading. It is useful when you need to add files from outside sources to Snowflake because it employs the COPY command.
Method 2: Data Loading to Snowflake Using SQL Commands
Using the Snowflake CLI and SQL commands in SnowSQL, you can bulk load massive amounts of data. Although this approach accepts input in a wide variety of formats, CSV Files are the most popular.
Method 3: Utilizing the Web Interface to Load Data into Snowflake
A constrained quantity of data can be loaded through the web interface. It comes with a LOAD button that may be used to enter data into Snowflake. This approach only works for small data sizes.
3. How to Manage Snowflake?
Once Snowflake is operational, you must look into:
Security Measures: Implement better security procedures for your company. Discretionary Access Control should be replaced with Snowflake’s role-based access control (RBAC) (DAC). Additionally, Snowflake enables SSO and federated authentication, interacting with third-party systems like Oakta and Active Directory.
Access Control: Establish a hierarchical framework for your users and applications by identifying user groups, necessary roles, and rights.
Resource Monitors: resource watchers with Snowflake, storage and computation are infinitely scalable. But in order to keep your business operational budget under control, you must set up surveillance and control procedures. Here, two factors stand out in particular:
- Timely alerts: assist with keeping track of and taking the appropriate measures when necessary. Create resource monitors to track your spending and prevent overcharging. Based on several threshold circumstances, you can alter these notifications and actions. Simple email alerts to deactivating a warehouse are among the options.
- Snowflake warehouse arrangement: For every system user, business region, or software, it is typically better to construct a dedicated Snowflake Warehouse. When necessary, this aids in managing chargebacks and separate billing. Configure responsibilities relevant to warehouse operations (access, monitor, update, and creation) to further tighten control and ensure that only authorized individuals can modify or build the warehouses.
Conclusion
An enterprise would need to make a large investment in IT tools and knowledge in order to have the storage capacity and compute power that Snowflake offers out-of-the-box. These companies can use Snowflake without worrying about the hardware or upkeep costs. For most businesses, the advantages of cloud computing outweigh the cost of subscriptions.
Companies across a range of industries must improve their data platforms in order to take advantage of new and forthcoming tools and apps. They have better access to their data and more advanced analytics with Snowflake, which help them grow their businesses.
To transform the data ingestion, storage, compliance and sharing for your business, talk to us.
- Zero-maintenance solution and seamless scaling
- Data-driven insights for improved operability and decision-making.
Get in touch with us to start today.



